Attention Is All You Need
Problem Statement
Recurrent neural networks (RNN) and variants have firmly established themselves as state-of-the-art approaches in sequence modeling and transduction problems such as language modeling and machine translation. Their inherently sequential nature, however, precludes parallelization within training examples, which becomes critical as sequence lengths increase and memory constraints limit batching across examples. In various tasks, attention mechanisms have become an integral part of sequence modeling and transduction models, allowing modeling of dependencies regardless of their distance in the input or output sequences.
The paper proposes the transformer, a novel model architecture that eschews recurrence and instead relies solely on attention mechanisms to learn global dependencies between input and output and overcomes the parallelization problem. The transformer achieves a new state-of-the-art in machine translation and other NLP related tasks.
Current Approach
The Transformer follows the overall encoder-decoder architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure below:
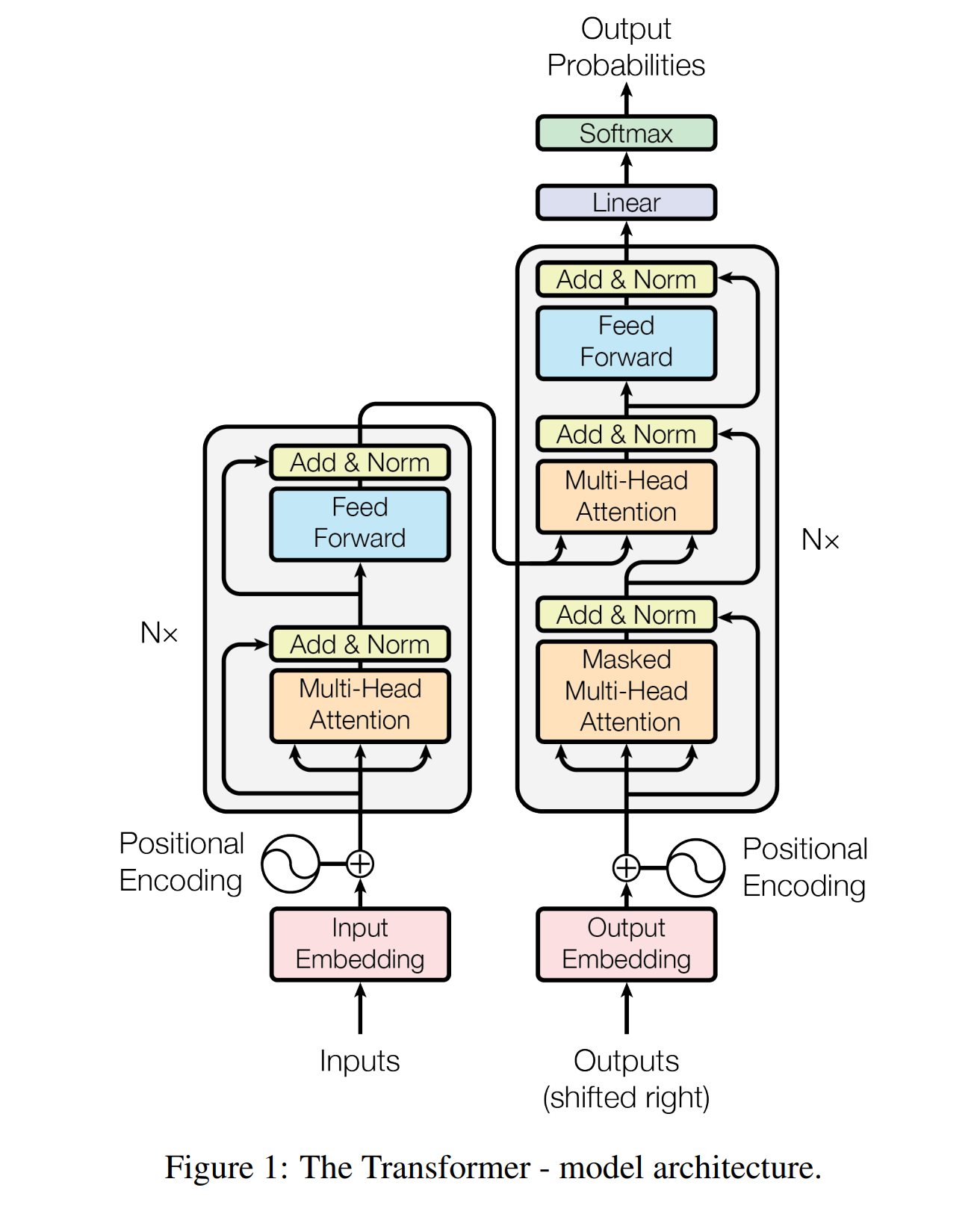
Encoder
The vanilla transformer architecture uses N = 6 encoder layers where each layer consists of 2 sub-layers, a multi-head self-attention mechanism, and a position-wise fully connected feed-forward network. Around each sub-layer, a residual connection is employed. Afterward follows a layer normalization. The final output of each sub-layer: LayerNorm(x + Sublayer(x)). All embedding layers as well as all sub-layers in the model produce outputs of the dimension dmodel=512.
Decoder
The difference of decoder form encoder is that it applies an additional third sublayer which performs multi-head attention over the output of the encoder stack. Again, residual connections are employed around each sub-layer followed by layer normalization. The self-attention sub-layer in the decoder stack is modified to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position can depend only on the known outputs at positions less than i.
Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query Q, keys K, values V, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Scaled Dot-Product Attention
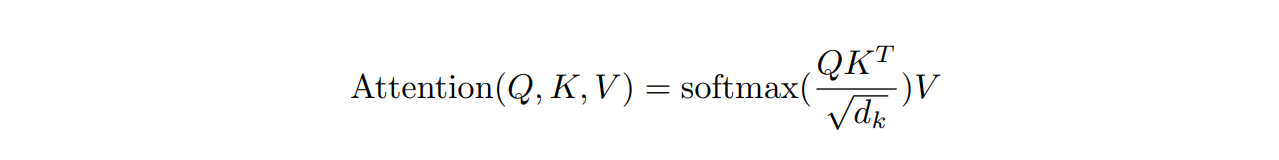
Where, dk is the dimension of keys K
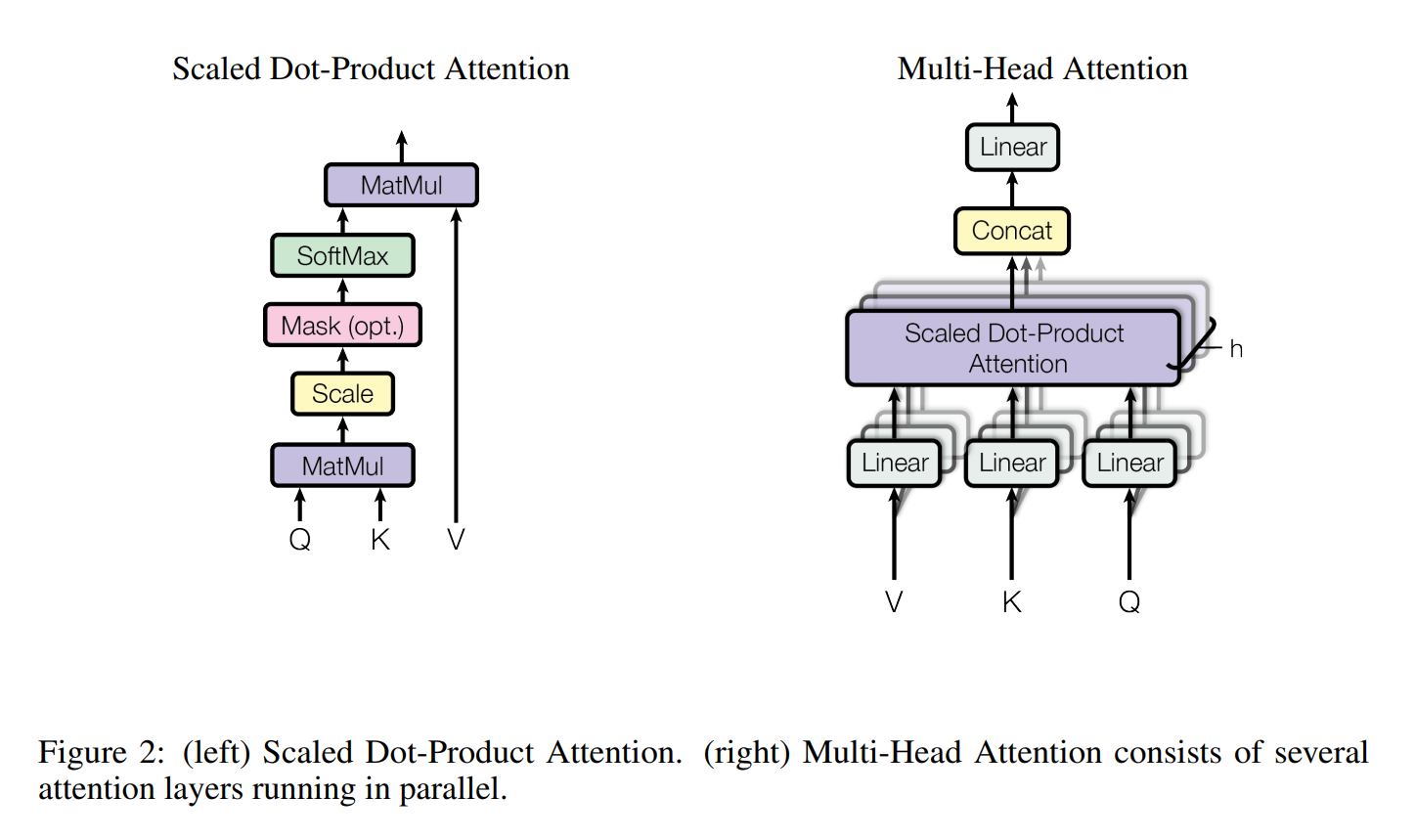
Multi-Head Attention

Multi-head attention is a way to project the queries, keys, and values into higher dimensions by learning separate attention heads. An attention head is basically the result of single-scaled dot-product attention. Multiple of those heads are then concatenated and weighted through an additional weight matrix W0. This process enables the Transformer to jointly attend to different representation subspaces and positions.
Positional Encoding
The transformer model contains no recurrence and no convolution, so, in order for the model to make use of the order of the sequence, “positional encoding” is added to inject some information about the relative or absolute position of the tokens in the sequence. For this, sine and cosine functions of different frequencies are used.
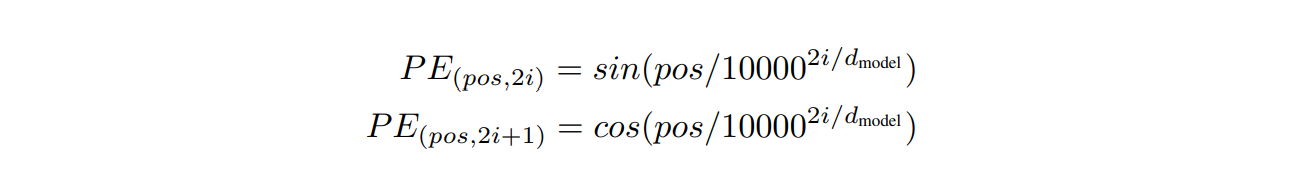
where pos is the position, dmodel is the dimension and is the dimension of the embeddings.
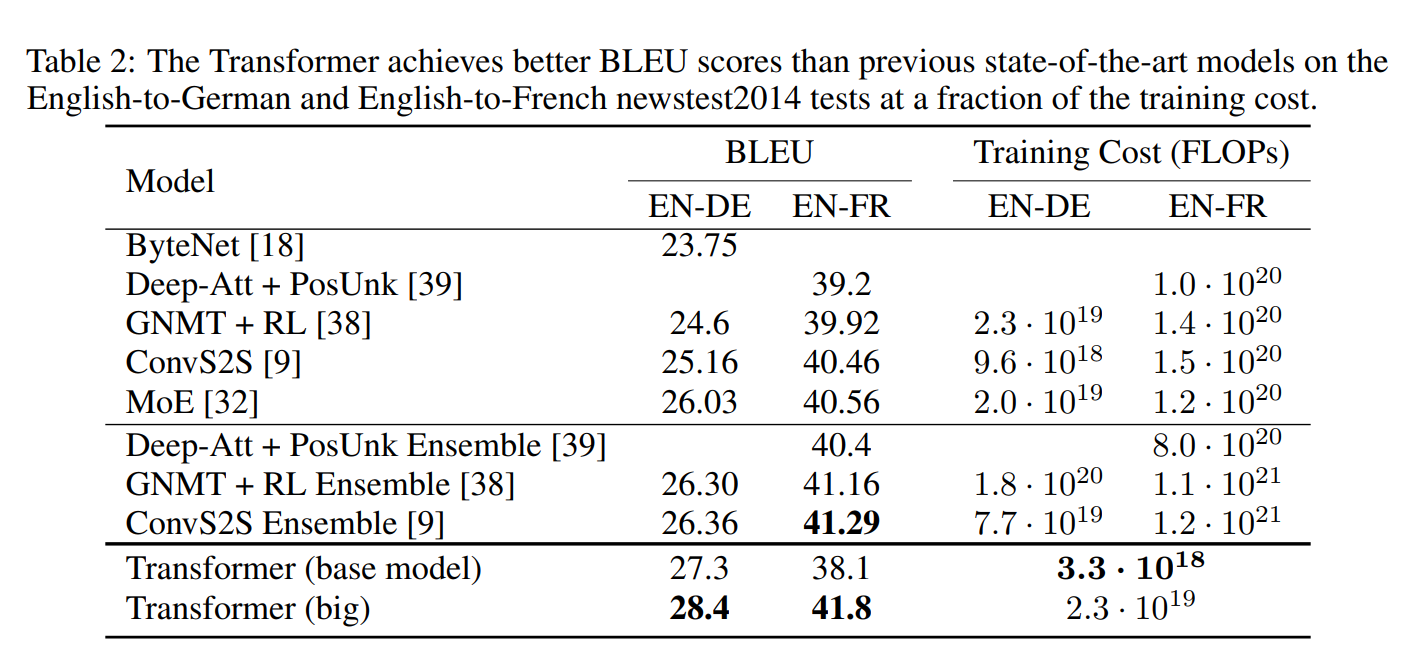
Result
WMT 2014 English-to-German translation task
- New state of art BLEU score of 28.4
- Training took 3.5 days on 8 P100 GPUs
- The base model surpasses all previously published models and ensembles
WMT 2014 English-to-French translation task
- The model achieves a BLEU score of 41.0
- Outperformed all of the previously published single models, at less than 1/4 the training cost of the previous state-of-the-art model.
- Used dropout rate Pdrop=0.1, instead of 0.3.
Conclusion
The Transformer architecture is the first entirely attention-based sequence transduction model. It replaces the most common recurrent layers in encoder-decoder architectures with multi-headed self-attention. It supports parallelization, which speeds up training, and the attention mechanism aids in capturing long-term dependencies between words in a sentence. Attention, on the other hand, can only handle fixed-length text strings. Before being fed into the system as input, the text must be divided into a certain number of segments or chunks. Text chunking causes context fragmentation. The above limitation can be addressed by using an improved transformer architecture described in Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
